Developers spend at least one third of their time working on the so-called technical debt [1,2,3]. It would make sense then that non-technical people working with developers had a good understanding of an activity that takes so much of their time. However, this abstract concept remains elusive for many.
I believe this problem has to do with the name "technical debt" itself. Many people are unfamiliar with debt, and thinking of how debt applies to software is not straighforward. But there is a concept that is way more familiar and might be more familiar: clutter. In software, as in any other aspect of life, clutter follows three basic rules:
- It increases with normal operation.
- Accumulating it leads to inneficiencies.
- Managing it in batches is time efficient.
Think of how it applies to house clutter: (1) everyday life tends to get your house messier if nothing is done to prevent it, (2) a messy home makes your day to day slower, and (3) the total time required to clean twenty dishes once is less than cleaning one dish twenty times. I empirically measured myself in this endeavor; it took me 5:10 to clean twenty dishes, versus the 15:31 that I spent cleaning them one by one over the course of multiple days.

The things I do for science
Due to the third rule, keeping the clutter at zero is a suboptimal strategy. I guess this is why in any given workplace we find clutter to some extent; think of office desks, factory workshops, computer files, email inboxes… and codebases. Just as it's inefficient to clean a single dish immediately after every use, in software development, addressing every instance of technical debt or "code clutter" as soon as it arises is not always practical or beneficial.
However, due to the second rule, letting the clutter grow indefinitely is also not a good strategy, because the inneficiencies created by the clutter can be bigger than the time required to keep it at bay. One of the hardest tasks in management is striking a good balance between both, because it's all about solving this optimization problem.
To find the optimum amount of clutter, you'd need to know how much does clutter grow depending on which operation you do, and how much easier it is to reduce clutter when you have more of it. But none of those two parameters is easily readable when looking at a project, so the way to steer a project is usually based in prior trial-and-error. Plus, those parameters are not static over time, which just makes it even worse.
I have seen many practices targeted at keeping technical clutter at bay, such as dedicating a day each week or allocating a percentage of the sprint backlog for refactoring. But I haven't found any foolproof data-based method for managing it, maybe because the distiction between adding new functionalities and de-cluttering is not always clear-cut and that makes it hard to report on.
What is clear is that, managing clutter requires a shift in the way we see it: it's not an accidental problem introduced by inneficient development, but rather an unavoidable byproduct of development.
No comments
The suggestions coming from Github Copilot look sometimes like alien technology, particularly when some incomprehensible code actually works. Recently, I stumbled upon this little excerpt that tests if a number is prime (and it actually works):

The ways of the universe are mysterious
Let's dissect the expression to understand it a bit better. First, the number that we are trying to check is converted into a sequence of that same amount of ones with '1'.repeat(n). Hence, the number 6 becomes 111111. We can already see why this is a fun trivia and not something you should be using in your code (imagine testing for 1e20), and why should always inspect the code from Copilot.
This list of ones is tested against the regex, so that if there is some match, the number is not prime. If you're not very used to regular expressions, I suggest learning it with some resource like RegexOne or Regex Golf; it's one of those tools that come in handy regardless of the technology you use, either to test strings or to find and replace stuff quickly. It's combines really well with the multiple cursors from modern IDEs.
The regex /^1?$|^(11+?)\1+$/ will then only match non-prime numbers, so let's inspect it. First, it can be split into two expressions separated by a disjunction operator |. The first is ^1?$, which will match zero or one, the first two non-prime natural numbers. Then, ^(11+?)\1+$, which is where the magic occurs. The first part (11+?) will match a sequence of two or more ones, but in a non-greedy way, so that it will match the smallest possible sequence. The second part \1+ will then match the same sequence repeated one or more times.
Since the whole expression is anchored to the beginning and the end of the string using ^ and $, it will only match strings made of some sequence that is repeated a number of times. And how can a sequence be a repeated a number of times? Well, not being a prime number. For instance, in the case of 6, the sequence 11 is repeated three times, so it matches the expression, because 6 is the product of 2*3.
^1?$
|
^
(11+?)
\1+
$
The original trick was developed in 1998 by @Abigail, a hacker very involved in the development of Perl, who keeps writing wild regex solutions to problems such as such as completing a sudoku or solving the N-Queens problem to this day. This expression is resurrected every few years, puzzling new generations of programmers. The next time you see one of these AI weird suggestions, if you pause to inspect it and do a bit of code archeology, you might find another piece of programming history.
Related posts:
No comments
After many years of making backends for one or another project, I find myself I keep frequently writing the same boilerplate code. Even if I tend to reuse my templates, the code ends up diverging enough to make switching between projects take some headspace. In an attempt to solve this, I created oink.php, a single-file PHP framework focused on speed and simplicity when building JSON APIs and web services.
function comment_create() {
$post_id = id("post_id");
$author = email("author");
$text = str("text", min: 5, max: 100);
check(DB\post_exists($post_id), "postNotFound");
return ["id" => DB\create_comment($post_id, $author, $text)];
}
That simple function is enough to create an endpoint with route /comment/create that takes three parameters post_id, author and text, validates them, and returns a JSON with the id of the new post. And to run it, you just need to add the oink.php file to your root folder, and point it to the file that defines your endpoints.
This library borrows some ideas I've been using in my personal projects for a while to speed up development. First, the routing is made by mapping API paths to function names, so I skip the step of creating and maintaining a route table. Also, all endpoints are method-agnostic, so it doesn't matter if they are called using GET, POST, DELETE or any other method; the mapping will be correct.
I also merge POST params, JSON data, files, cookies and even headers into a single key-value object that I access through the validation functions. For example, calling str("text", min: 5, max: 100) will look in the request for a "text" parameter, and validate that it is a string between 5 and 100 characters, or send a 400 error otherwise.
These tricks are highly non-standard and create some limitations, but none of them is unsolvable. This attempt of placing dev speed before everything else, including best practices, is what made me think of Oink as a good name for it. The library should feel like a pig in the mud: simple and comfortable, even though it's not the cleanest thing in the world.

Most of Oink's code comes from battle-tested templates I have been using for my personal projects. This blog's server, which also hosts several other applications, manages around 2000 requests per hour. Despite DDOS attempts or sudden increases in traffic, the server's CPU and memory usage rarely exceeds 5%, thanks to the good ol' LAMP stack. While my professional projects often utilize Python, the scalability and maintainability of running multiple PHP projects on a single Apache server showcases the stack's efficiency. It's evident why PHP still ranks the most used backend language in most reports.
To explore oink.php further or contribute to its development, visit the GitHub repository. While I recommend frameworks like Laravel or Symfony for larger enterprise projects needing scalability, Oink offers a compelling alternative for developers prioritizing speed and simplicity.
No comments
I believe we are at the threshold of a new programming paradigm. As the latest advancements in AI make it more accessible and closer to a self-hosted utility, we are entering a world in which developers can articulate what they want to achieve in simple natural language terms. I call this paradigm semantic programming.
No one can deny that LLMs have disrupted the way developers code. By July '23, Github reported that 92% of all polled devs were using AI in their work. By November, Snyk reported it was already 96%. The exact figure may vary, but I think it's safe to say most developers are already using AI in their day to day.
I have seen two prominent ways of integrating AI into the workflow. The first is using chatbots like ChatGPT or Bard as a Q&A oracle to which you send your questions or ask for code. The second is as a linter on steroids that you install in your IDE and constantly gives you suggestions coming from a model trained for code completion.
In both scenarios, the workflow involves sending a request to a server—often a supercomputer—that hosts a humungous model trained on vast amounts of data. While there are smaller, self-hostable models, they perform poorly on most AI leaderboards, despite being quite resource-intensive. This is a grim reality, as only big players are able to offer useful AI these days, since the cost of running inference is too high for domestic computers.
It's hard to determine when it will be reasonable to run a good enough pre-trained model locally, because of the constant pace of breakthroughs we're seeing, such as quantization, mixture of experts, LoRAs or distillation. But even if we just consider Moore's Law, it seems it will be a reality soon enough. And when that happens, maybe semantic programming becomes the new normal:
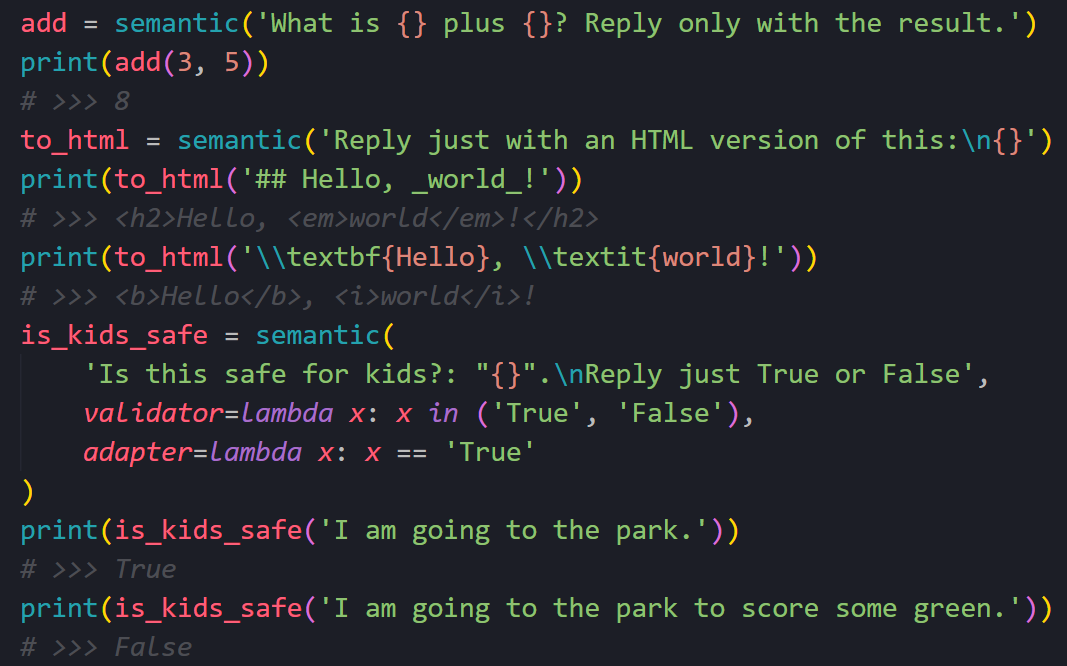
I know, using a trillion-parameter neural network to add three plus five seems cumbersome, even triggering. But so does shipping Chromium with every desktop app just to ignore platform compatibility, yet today it's standard practice with frameworks like Electron. Computer science is a tale of programmers embracing lazy abstractions whenever hardware gets faster.
The add example is an overkill for illustration, and I hope we don't do basic arithmetic this way anytime soon. But methods like to_html would require much more time to handcraft, if that's even possible. Maybe semantic programming becomes simply another tool in the set, same as other niche paradigms like constraint or symbolic programming.
Quality-wise, the main problem is how unreliable the output is. We could have next-token limitations tailored to the problem. For instance, we limit tokens for is_kids_safe output to be either 1 or 0, or dynamically constrain the next token for to_html to adjust to some regex for valid HTML. But these ideas won't get us any further in having a formal understanding of the reasoning behind each answer, nor will it give us mathematical certainity that the algorithm is correct.
Performance-wise, it's easy to see its limitations. Running this tiny example available here requires sending 109 tokens and getting 33 back, which costs $0.000104 with GPT-3.5. This is not a huge price for complex operations with short outputs like is_kids_safe, but longer texts or frequent calls could make the costs add up. Plus, server round trips take ~100ms, which is less than ideal for some seamless code integrations.
Despite all these problems, I'm really excited about this new way of coding. It enables functionalities that were plainly impossible before, like this anything-to-HTML converter. It democratizes coding, allowing people with no previous experience to craft on their own solutions. It shines in contexts where we can be tolerant to errors but can also work in critical contexts, such as law or medicine, by transforming human labor into supervision tasks. And most importantly, it enables, for the first time in history, a way to embed human intuition into code.
7 comments
I've become a huge an of a platformer game called Noita, where every pixel is a dynamic part of a simulation. These pixels can interact with each other and the player in complex and often unpredictable ways. You're plunged into a procedurally generated cave, that you have to explore and descend into its depths. It seems like the game was governed by realistic physics material interactions: oil ignites, ice melts, metal rusts, gases explode, and acid dissolves almost anything, including the player. And mostly everything kills you.

This intricate simulation is powered by a custom-built game engine fittingly named Falling Everything. I was curious about how it would handle such a vast array of interactions, and I was surprised by the elegant simplicity of its design. Basic particle interactions, governed by a few rules, result in rich, emergent behaviors. This inspired me to create a simplified version of the engine.
Drag to add sand
Consider sand in our simulator: it moves to an empty pixel below or, if blocked, to the diagonals. This basic rule simulates gravity and creates piles of sand in which new grains slide down. Since sand always goes down and never up, you can just scan the map from top to bottom and move each grain down until it's blocked.
Drag to add water
Water follows a similar logic: it tries to move down like sand, but if blocked, it tries to move sideways; this is, swapping places with a pixel to the left or right if it's empty. This creates a fluid that flows downwards and sideways, stabilizing into a flat surface. We can allow sand to swap places with water but not the other way around, so sand can't sink into water. This is how the game handles liquids and their interactions with solids.
Choose particle types with the left palette
Expanding this system is equally rewarding. Gases are just water that flows upwards. Walls don't interact with anything. Fire just disappears if random() > 0.8, spreads through gas, and when touching water both become gas particles. It's not hard to imagine how this could be extended to other elements that follow simple rules like grass, lava, ice, or electricity.
Feel free to check out the fullscreen version of this tiny simulator. It only contains these six basic particles but it's already fun to play with. You can also extend it if you want, the whole thing is a single HTML file, but don't expect the cleanest code ever as it was a 3 hour hack.
In general, I think this is an interesting approach to world designs with so much untapped potential for videogames, probably due to its unpredictability. And it would be interesting to port this to a 3D world, probably using higher-level memoizations akin to Hashlife to process more than one pixel at a time.
No comments