Tuenti Challenge 10
Del 27 al 4 de mayo se ha celebrado la décima edición del reto para programadores que organiza Tuenti todos los años. Suelo participar siempre porque se sale de los esquemas habituales de los concursos de programación y eso lo hace muy divertido.

En este mega-post describo cómo he resuelto los primeros 18 problemas. Podéis encontrar mi solución a todos los problemas en su repo de Github.
Introducción
Estos concursos suelen seguir la estructura que inventó ICPC, que consiste en resolviendo problemas algorítmicos a partir de una descripción y un archivo de entrada. Este archivo contiene muchos casos de prueba que hay que interpretar para generar otro archivo de salida. Otros concursos de este tipo son Google Code Jam o Facebook Hacker Cup.
Otros siguen la estructura CTF, que consiste en encontrar una clave escondida tras un archivo o la IP de un servidor. Al no tener enunciado, es necesario aplicar el pensamiento lateral y tener ciertos conocimientos sobre un tema. Hay muchos CTF sobre seguridad informática al año.
Tuenti Challenge destaca por la variedad de problemas de ambos tipos. En esta edición ha habido niveles tales como una escape room via SSH a un servidor que sólo funciona con emojis, calcular el CRC32 de archivos de 200GB ultra-comprimidos o construir el mayor castillo de papel higiénico posible con los rollos de un supermercado.
Nivel 1: Rock, Paper, Scissors
El primer problema suele ser algo simple para ir calentando, así que voy a aprovechar para explicar cómo proceso la entrada y genero la salida. Suelo resolver todos los problemas usando Python por su cercanía al pseudocódigo que hace tan fácil probar nuevas ideas rápidamente.
El problema consiste en averiguar qué figura ganaría en un juego de piedra, papel o tijera. Al ser un problema en formato ICPC, la entrada es un archivo de texto cuya primera línea es el número de casos N (partidas de piedra, papel o tijera) y cada una de las N siguientes líneas se corresponde a un caso.
4
R S
R P
P P
S P
Con una entrada como la anterior, debemos generar un archivo de salida en el que cada línea sea el resultado de uno de los casos siguiendo el formato Case #n: result. Para nuestro ejemplo, la salida esperada es la figura ganadora, o - en caso de empate.
Case #1: R
Case #2: P
Case #3: -
Case #4: S
Primero debemos procesar un archivo de prueba llamado testInput.txt que contiene unos pocos casos pequeños. Cuando lo resolvemos, obtenemos el archivo submitInput.txt en el mismo formato y con muchos más —y casi siempre más complejos— casos de prueba. La idea es usar el test para comprobar que nuestro algoritmo funciona bien, y el submit para que puedan evaluar nuestra solución.
FNAME = 'test'
def load_input():
with open('%sInput.txt' % FNAME, 'r', encoding='utf-8') as fp:
problems = int(fp.readline())
for p in range(problems):
yield sorted(fp.readline().strip().split(' '))
Esta es la forma en la que suelo cargar el archivo de entrada en estos problemas. Ir iterando línea a línea y usar un generador mediante la sentencia yield hace que estos problemas se procesen de una forma muy natural. En ninguno de ellos he tenido que dedicar demasiado tiempo a adaptar la entrada y eso me permite centrarme en el problema. El único tuning que ha sufrido en este caso es la función sorted, que me asegura que las figuras de la partida lleguen en orden alfabético.
def main():
output = ''
for p, problem in enumerate(load_input(), 1):
print('Solving case #%d' % p)
output += 'Case #%d: %s\n' % (p, solve(*problem))
with open('%sOutput.txt' % FNAME, 'w', encoding='utf-8') as fp:
fp.write(output)
La función main es el punto de entrada de este script, y va leyendo los problemas uno a uno para obtener su solución llamando a la función solve. Al usar el operador * como argumento de solve, esta función recibe como entrada los mismos parámetros que devuelve el generador.
def solve(p1, p2):
if p1 == 'R' and p2 == 'S':
return 'R' # rock beats scissors
elif p1 == 'P' and p2 == 'R':
return 'P' # paper beats rock
elif p1 == 'P' and p2 == 'S':
return 'S' # scissors beats paper
else:
return '-' # it's a draw
Sabiendo que las figuras de ambos jugadores llegan ordenadas, la solución se obtiene de forma muy sencilla. Y con esto podemos resolver el problema de test, descargar el archivo submit y cambiar FNAME para procesarlo de la misma forma.
Nivel 2: The Lucky One
Este nivel en formato ICPC nos da como entrada una lista de partidas de ping-pong y tenemos que averiguar cuál es el mejor jugador. Como el problema asegura que la solución es única y que no es posible el empate, podemos deducir que hay un jugador que nunca ha perdido una partida.
def solve(matches):
players = set()
losers = set()
for p0, p1, p1_loser in matches:
players.update((p0, p1))
losers.add(p1 if p1_loser else p0)
return max(players.difference(losers))
Así, podemos ir recorriendo la lista de partidas creando un conjunto de jugadores que hemos visto y otro de jugadores que han perdido alguna vez. Tras iterar sobre todas las partidas, el mejor jugador es el único del conjunto de jugadores que no aparece en el de perdedores.
Nivel 3: Fortunata and Jacinta
Este nivel es un homenaje al novelista Pérez Galdós en el centenario de su muerte. Dada una versión en txt de su novela magna, tenemos que convertir a minúsculas todo el documento, identificar las palabras como un conjunto de tres o más letras del alfabeto español y ordenarlas por frecuencia siguiendo el orden unicode en caso de empate.
from collections import Counter # frequency counter
from regex import compile # unicode-aware regex library
REMOVE_INVALID = compile(r'[^abcdefghijklmnñopqrstuvwxyzáéíóúü]+').sub
SPACE_SPLIT = compile(r'\s+').split
_ctx_by_word = {}
_ctx_by_rank = {}
def load_context():
global _ctx_by_word, _ctx_by_rank
text = SPACE_SPLIT(REMOVE_INVALID(' ', text).strip())
text = [word for word in sorted(text) if len(word) >= 3]
text = Counter(text).most_common()
for rank, (word, frequency) in enumerate(text, 1):
_ctx_by_word[word] = '%d #%d' % (frequency, rank)
_ctx_by_rank[rank] = '%s %d' % (word, frequency)
Para crear este ranking he usado una expresión regular para reemplazar por espacios todos los caracteres no deseados y otra para separar las palabras. Después, la librería built-in collections nos permite crear un ranking por frecuencia sin esfuerzo, y con él construir los dos rankings que necesitamos para este problema:
- Dado un número, la palabra que ocupa esa posición en el ranking y su frecuencia.
- Dada una palabra, su frecuencia y su posición en el ranking.
def solve(line):
if line.isnumeric():
return _ctx_by_rank[int(line)]
else:
return _ctx_by_word[line]
Habiendo construido estos rankings al empezar, la resolución del problema es así de simple. Sólo tenemos que ver si la entrada es un número para devolver una salida u otra.
Nivel 4: My Favorite Video Game
Aquí empiezan los problemas que se salen de lo habitual. Este nivel de tipo CTF nos habla de una compañía de videojuegos llamada Steam-Origin (como si Valve y EA no fueran suficientemente grandes por sí solas), que tiene una API para obtener claves de sus juegos.
$ curl steam-origin.contest.tuenti.net:9876/games/free_shoot/get_key
{"game":"Free Shoot","key":"9999-9999-9999"}
La compañía es conocida por sus fallos de seguridad, y la semana que viene va a publicar su nuevo juego, Cat Fight, que quieres conseguir a toda costa. Recientemente han publicado una presentación técnica en Prezi que revela información clave para conseguir el juego antes que nadie.

Sus entornos de pre- y producción comparten la base de datos y un balanceador de carga externo, pero al de preproducción sólo se puede acceder desde su VPN en la dirección pre.steam-origin.contest.tuenti.net. Este balanceador de carga no está muy fino:
from requests import get
URL = 'http://steam-origin.contest.tuenti.net:9876/games/cat_fight/get_key'
HEADERS = {'Host': 'pre.steam-origin.contest.tuenti.net:9876'}
data = get(URL, headers=HEADERS).json()
with open('key.txt', 'w') as fp:
fp.write(data['key'])
La cabecera Host ayuda al servidor a identificar a qué dominio se está enviando cierta petición de entre los alojados en un servidor. Esta cabecera es suficiente para confundir al balanceador de carga, hacerle creer que estamos dentro de la VPN y obtener sin restricciones una clave del juego.
Nivel 5: Tuentistic Numbers
Se define un número "tuentístico" como aquel que pronunciado en inglés contiene la palabra twenty. Por ejemplo, 20, 21 o 120000 son números tuentísticos. Dado un número entre 1 y 262, debemos averiguar cuál es la mayor suma de números tuentísticos que lo representa.
Este es el primer problema en el que los límites empiezan a ser relevantes. Con números tan grandes como 262 no nos podemos plantear probar todas las sumas posibles. En su lugar, debemos buscar una simplificación que nos permita hacer este cálculo rápidamente.
Una posibilidad es usar sólo los números tuentísticos más pequeños; aquellos entre 20 y 29. De esta forma, la menor cantidad de números a sumar será siempre n / 29 y la mayor cantidad será n / 20, redondeando hacia abajo.
def solve(n):
mn = n // 29 + (1 if n % 29 else 0)
mx = n // 20
if mn > mx:
return 'IMPOSSIBLE'
else:
return mx
Y esto es todo lo que debemos hacer, considerando un par de excepciones: si el número no es divisible entre 29, tendremos que añadir un término más a la suma, y si la menor cantidad de números a sumar es mayor que la mayor cantidad, este problema es imposible.
Nivel 6: Knight Labyrinth
De nuevo un nivel de tipo CTF, que me resultó especialmente divertido. Dada una IP para acceder a un laberinto en formato texto que sólo nos muestra las casillas de nuestro alrededor, debemos movernos por ellas mediante el salto del caballo de ajedrez para rescatar a una princesa.
En esta ocasión he intentado llegar a la solución más rápida posible haciendo algunas optimizaciones:
- Como el servidor permite hasta 10 conexiones desde una misma IP, podemos usar una escuadra de 10 caballeros.
- Para calcular el camino a una casilla en caso de que lo haya, construimos un grafo en el que los nodos son las casillas y hay una arista por cada par de casillas comunicadas.
- Los caballeros siempre se mueven hacia una casilla objetivo, y al llegar a ella se fijan un nuevo objetivo.
- Dos caballeros nunca comparten un mismo objetivo, y si no quedan objetivos disponibles se quedan parados esperando.
- La princesa es el objetivo prioritario.
- Mientras no sea posible llegar a la princesa, se toma como objetivo la casilla más cercana con más casillas por descubrir a su alrededor.
- Voy guardando en un archivo de texto el tablero del juego, para no caer dos veces en la misma trampa. Al ver el laberinto completo me encontré una curiosa sorpresa.

Nivel 7: Encrypted lines
En este nivel aparecen dos líneas de un texto que debemos desencriptar, acompañadas de una pista de audio para que "resolvamos el problema de forma mucho más agradable". Supe de inmediato que la pista de audio es la Sinfonía del Nuevo Mundo de Antonín Dvořák, porque fue mi despertador durante un tiempo (nada recomendable para levantarse con buen humor).
yd. b., ,rpne ofmldrbf ,ao jrmlro.e xf abyrbcb ekrpatv
yd. ekrpat ocmlncuc.e t.fxrape ,ao lay.by.e xf agigoy ekrpat abe dco xpryd.p cb na, ,cnncam e.an.fv
Algunos trozos de la cadena como yd., ,ao o xf se repiten varias veces. Además, los símbolos a, . y r son bastante frecuentes. Todo esto puede hacernos sospechar que se trata de un cifrado por reemplazo, y podríamos solucionar el problema mediante análisis de frecuencia.
Sin embargo, la pista de audio nos revela algo más: Dvorak es también el nombre de una distribución de teclado famosa entre los programadores por ser especialmente ergonómica, siempre que superemos la penitencia de dejar de usar QWERTY.

Si reemplazamos cada letra del teclado Dvorak por la que ocupa la misma posición en el teclado QWERTY, desencriptaremos el texto y encontraremos la respuesta al problema.
Nivel 8: Headache
Este nivel es un CTF de los clásicos, en el que nos dan una imagen que tiene una clave escondida. Aparentemente, la imagen está en blanco, pero al subir el contraste a tope aparece esto:

Esta no es la clave que buscamos. Si la abrimos con un editor hexadecimal y miramos el campo de comentarios del PNG, nos encontramos el texto "Hi challenger! No, the code is not here ;)". Pero al final del archivo hay una cadena bastante sospechosa.
++++++++++[>++++++>+++++++>++++++++>+++>+<<<<<-]>>>++++.<++.---.>>++.<<-
-.>-----.<+.+.>>.<<++++.>++++.<<--.>>>.<++++.<++++++.---.+++.---.+++.>>+
Si alguna vez habéis visto código en lenguaje esotérico Brainfuck lo habréis identificado de inmediato (sí, esto es un lenguaje de programación). Podemos pegar este texto en un intérprete online de Brainfuck y obtendremos la clave del problema.
Nivel 9: Just Another Day on Battlestar Galactica
Nos encontramos en medio de una batalla entre los robots cylons y los humanos de Battlestar Galactica, la nave de combate que protagoniza la serie homónima. Sabemos que las baterías de los cylons necesitan cierto isótopo radioactivo que se encuentra en unos pocos planetas.
Hace un año, los humanos interceptaron un mensaje cifrado de los cylons, y poco después estos aterrizaron en un planeta que albergaba el isótopo en cuestión. Conocemos las coordenadas de ese planeta.
MENSAJE: 3633363A33353B393038383C363236333635313A353336
PLANETA: 514;248;980;347;145;332
Recientemente, los humanos han interceptado otro mensaje que seguramente se corresponda a otro planeta. Además han encontrado un script bash con la función que usan para encriptar sus mensajes. ¿Podemos revertir la encriptación y descubrir las nuevas coordenadas?
Tras estudiar el script, vemos que su funcionamiento es el siguiente:
- Se introduce una clave secreta con la misma longitud que el mensaje.
- Cada símbolo del mensaje se transforma en su código ASCII.
- Se genera una nueva secuencia haciendo el XOR del mensaje y la clave.
- Se devuelve esta nueva secuencia, pasando a hexadecimal cada byte.
Como conté en el post sobre el cifrado XOR, este es un cifrado recíproco, de manera que T XOR P = C implica que C XOR P = T. Esto quiere decir que teniendo un mensaje en texto plano y su versión cifrada, podemos averiguar la clave de encripción y con ello descifrar el segundo mensaje.
Nivel 10: Villa Feristela escape room
Este me pareció el nivel más original de todo el concurso: una conexión por SSH a un servidor cuyos comandos funcionan sólo con emojis. Si no lo habéis probado no sigáis leyendo y probadlo, merece mucho la pena.
En este problema somos un detective que ha llegado a un hotel-castillo llamado Villa Feristela, y debemos resolver un misterio. La mayor parte de las interacciones con el juego se hacen mediante emojis. Como no quiero arruinarle este juego a nadie, sólo voy a mencionar las guías necesarias para superar este nivel, sin entrar en mucho detalle.
- La linterna 🔦 es el comando
ls, y sirve para encontrar todas las estancias —directorios— a las que podemos acceder y todos los personajes —archivos— con los que podemos hablar. Puedes acompañarlo de todas sus opciones habituales, como-Apara mostrar todos los elementos ocultos, o🔦 */* -Alhpara listar todas las estancias. - El corredor 🚶 es el comando
cd, y podemos usarlo para entrar en una estancia. Podemos hacer🚶 ..para volver a la estancia superior. - La mano ✋ se usa para coger objetos. Es fácil confundirse e intentar usar el otro emoji de mano.
- El zombie 🧟 nos propone un acertijo que se puede resolver rápidamente por fuerza bruta. Para darle la respuesta debemos usar el comando echo 🗣 haciendo pipeline:
🗣 119 | 🧟. - El robot 🤖 nos pide su código de error. La variable
$?guarda el exit code del último comando ejecutado. Para decirle al robot su código de error podemos usar de nuevo el comando echo:🗣 $? | 🤖. - El genio 🧞 se despierta suavemente si usamos Ctrl+Z para enviar la señal SIGTSTP en lugar del brusco SIGINT que envía Ctrl+C.
- La lupa 🔎 nos permite leer el texto del rollo de papel del baño.
- La mariquita 🐞 se esconde en el agujero del cuarto de baño. Como ahí dentro no se ve nada, tendrás que cogerlo desde fuera:
✋ 🕳/🐞.
Y con esto es suficiente para resolver este problema. Para poder incluir todos estos emojis en esta entrada he tenido que cambiar el formato de algunos campos de la BD del blog a utf8mb4. Espero que os haya gustado, nos vemos en el siguiente post de esta serie!
Nivel 11: All the Possibilities
Este es uno de esos posts que esconden cierta complejidad bajo la simpleza de su enunciado: dado un número X entre 1 y 100 y algunos números Ni menores a este, calcular de cuántas formas se puede representar X como suma de enteros que no contengan ningún Ni. En matemáticas, una suma de enteros que da lugar a un número se denomina una partición.
def solve(X, N):
res = [1] + [0] * X
for i in range(1, X): # in how many ways you can use an i...
if i not in N:
for j in range(i, X + 1): # ...to obtain j
res[j] += res[j - i]
return res[X]
La solución también parece sencilla aunque esconde cierta complejidad. La mejor forma de entenderlo con un ejemplo: vamos a calcular cuántas formas hay de sumar 5 sin usar el número 3.
Primero, construiremos una array res en la que iremos guardando en cada posición j de cuántas formas se puede sumar dicho número. Como sólo hay una forma de sumar cero, res = [1, 0, 0, 0, 0, 0].
A continuación, iremos viendo cuántas formas hay de sumar el número en posición j usando sólo el número 1 y actualizaremos res sumándole estos valores.
- Para sumar 1 sólo hay una suma posible:
[1, 1, 0, 0, 0, 0]. - Para sumar 2 sólo hay una suma posible, 1+1:
[1, 1, 1, 0, 0]. - Para sumar 3 sólo hay una suma posible, 1+1+1:
[1, 1, 1, 1, 0]. - Para sumar 4 sólo hay una suma posible, 1+1+1+1:
[1, 1, 1, 1, 1, 0]. - Para sumar 4 sólo hay una suma posible, 1+1+1+1+1:
[1, 1, 1, 1, 1, 1].
Después, repetiremos la operación para el número dos. Como no podemos usar el 2 para sumar un número menor a sí mismo, empezaremos intentando sumar dos.
- Para sumar 2, sólo hay una suma posible:
[1, 1, 2, 1, 1, 1]. - Para sumar 3, sólo hay una suma posible, 2+1:
[1, 1, 2, 2, 1, 1]. - Para sumar 4, hay dos sumas posibles, 2+1+1 o 2+2. Y aquí está la clave del algoritmo. Como estamos iterando del número más pequeño al más grande, hay
res[j-i]formas de sumar cualquier número j usando el número i. Actualizamos nuestra array:[1, 1, 2, 2, 3, 1]. - Siguiendo con la regla anterior, hay tantas formas de usar un 2 para sumar 5 como tengamos en
res[5-2]. Así queres = [1, 1, 2, 2, 3, 3].
Como en este problema no podemos usar el número 3, nos lo saltamos y repetimos esta operación usando el número 4 para sumar 4 o 5.
- Para sumar 4, sólo hay una suma posible:
[1, 1, 2, 2, 4, 3]. - Para sumar 5, hay tantas formas de sumarlo usando un 4 como tengamos almacenado en
res[5-4]:[1, 1, 2, 2, 4, 4].
Al terminar esta operación, tenemos almacenado en el último valor de la array la solución al problema.
Nivel 12: Hackerman Origins
En este problema tenemos dos mensajes en texto plano y sus versiones cifradas usando RSA. Como hemos perdido la clave pública que hemos usado para cifrarlos, debemos encontrarla a partir de ambos pares de mensajes.
Este cifrado tan seguro es la base de nuestra comunicación. La usan bancos, VPNs, navegadores y hasta comunicaciones entre gobiernos. Si pudiéramos romperlo, ¿por qué conformarse con solucionar este problema? Por suerte, no tenemos que llegar tan lejos y basta con recuperar la clave pública, cuyo propósito no es ser especialmente segura.
Una clave pública RSA es un par (e, m). Dado un mensaje sin cifrar P, su cifrado consiste en convertirlo en un entero, elevarlo al exponente e, y aplicarle el módulo m dado. El número resultante es el texto cifrado C. En otras palabras, P e = C (mod m), o lo que es lo mismo P e - C = k m, donde k es algún número entero.
Por tanto, si tenemos dos pares de textos (P1, C1) y (P2, C2) y conocemos el exponente e, podríamos hallar su módulo mediante el máximo común divisor: m = gcd(P1e - C1, P2e - C2). Para encontrar el exponente usar el más habitual: 65537.
Nivel 13: The Great Toilet Paper Fortress
Debido al reciente afán por el acopio de papel higiénico, un supermercado ha decidido construir el mayor castillo de rollos de papel para tranquilizar a los compradores, siguiendo ciertas propiedades.
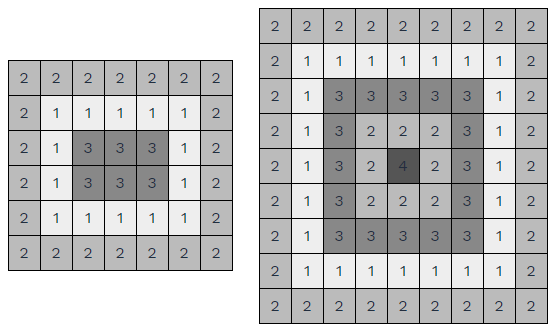
El castillo debe tener una torre central lo más alta posible, rodeada por una muralla con dos rollos menos de altura, rodeada por otra de un rollo más de altura y así sucesivamente. Este proceso termina cuando la siguiente muralla a construir tuviera que tener altura cero. Además, la torre central debe ser cuadrada o rectangular con sólo un rollo de diferencia entre ambas dimensiones.
Si asumimos que la torre central siempre tiene un único rollo en cada planta, podemos usar las propiedades de los sumatorios para calcular el número de rollos necesarios para hacer una torre de h rollos de altura.
def simple_rolls(h):
return (16 * h**3 - 36 * h**2 - h + 24) // 3
Ahora tenemos que ver cómo añadir rollos a la planta de la torre central. Como sólo puede haber un rollo de diferencia entre ambas dimensiones, la torre central debe ser siempre de 1x1, 1x2, 2x2, 2x3, 3x3, etc. Lo que significa que la suma del ancho y el largo siempre es distinta: 2, 3, 4, 5, 6, etc.
Si de nuevo nos peleamos un poco con las propiedades de los sumatorios mirando muchos ejemplos de castillos (el Excel fue de gran ayuda), podemos escribir una función que calcule cuántos rollos extra, aparte de los calculados por simple_rolls, necesitamos para hacer una torre cuya suma de dimensiones es s.
def extra_rolls(h, s):
if s == 0: return 0
return (2 * s) * (h**2 - h) - h + h * (s // 2 - 1 + s % 2) * (s // 2 - 1)
Teniendo estas dos ecuaciones, el problema se vuelve muy sencillo: devolvemos IMPOSSIBLE si nos dan menos de simple_rolls(3) rollos, y en otro caso encontramos el mayor h posible con los rollos que nos dan y vamos aumentando s para encontrar el mayor la mayor torre central.
Nivel 14: Public Safety Bureau
Este fue uno de los problemas más interesantes y complejos del concurso: muchos se lo saltaron, y otros tantos abandonaron en este problema. Es un CTF en el que sólo tenemos una IP y un puerto mediante los que conectarnos a un protocolo de consenso de red conocido como Paxos inspirado en el sistema Sibyl del anime Psycho-Pass.

El objetivo de este protocolo es establecer un acuerdo sobre cierto valor v, como podría ocurrir al actualizar el valor de un atributo en una base de datos distribuida. Tenemos una serie de servidores que tienen roles definidos. Los servidores se agrupan en conjuntos llamados quorums de forma solapada. Por ejemplo, un quorum puede estar formado por los servidores 1, 2 y 4; otro por los servidores 2, 3 y 5.
El protocolo va realizando pequeñas tareas una por una, que se realizan en paralelo por todos los servidores del quorum y se ponen en común para garantizar la consistencia. Veamos este proceso paxo a paxo (mis disculpas):
- La petición para actualizar un valor v surge de un servidor con el rol proposer, que contacta con todos los servidores de uno de sus quorums mediante un mensaje llamado PREPARE que va acompañado de un identificador numérico n que se va incrementando.
- Si los servidores que reciben el mensaje, cuyo rol es acceptor, no han recibido ningún n superior significa que el servidor está al día. En este caso, responden con un mensaje llamado PROMISE, acompañado del último valor v-1 que han visto, y actualizan su valor n.
- Cuando el proposer ha recibido una mayoría de promises, escoge el nuevo valor de acuerdo con los v-1 que ha recibido, y se lo envía a todos los servidores mediante un mensaje ACCEPT, que debe entenderse como "acepta este nuevo valor, por favor".
- Si este es el mensaje más nuevo que han encontrado, los acceptors enviarán un mensaje ACCEPTED al proposer, y el valor será actualizado en todos ellos.
Tras entender el protocolo, es necesario hacer muchas, muchas pruebas hasta entender cómo funciona su sintaxis en el servidor del problema. Además, este problema tiene una pequeña vuelta de tuerca en uso de este protocolo: el valor sobre el que ponerse de acuerdo no es ningún atributo en una base de datos, es una cadena que contiene la lista de servidores que se están usando y un valor secret_owner: 1 que apunta a un servidor que contiene un secreto.
ROUND 897: 5 -> ACCEPTED {servers: [1,2,3,4,6,7,8,9], secret_owner: 1}
La modificación del secret_owner debe ser aceptada por mayoría. Cada ciclo completo de Paxos nos permite añadir o eliminar un único servidor de la lista de servidores del quorum. Podemos ir eliminando servidores uno por uno para hacernos con el control de la red, pero al llegar a 3 servidores nos encontraremos un problema.
Cluster needs to have at least 3 members alive
No podemos garantizar la mayoría siendo un único servidor. Pero si nos conectamos con 2 o más servidores al mismo tiempo, podemos alcanzar esta mayoría. Así, podemos definir la siguiente estrategia:
- Un servidor maestro se conecta a la red, y es el que va imprimiendo la traza de su ejecución para que podamos entender el funcionamiento de la red.
- El resto de nuestros servidores esperan a que el maestro les añada a la lista de servidores, y a partir de ahí se limitan a aceptar todos los mensajes PROPOSE y ACCEPT que éste emita.
- Una vez añadidos todos nuestros servidores, debemos ir expulsando a todos los otros servidores excepto el
secret_owner. - Cuando nuestros servidores son mayoría, podemos realizar un ciclo de Paxos en el que se reemplace el
secret_ownerpor uno de los nuestros.
Y con esto recibiremos el mensaje secreto, que es una cita de Psycho-Pass. Tras indagar un poco sobre este anime para este problema, he terminado por engancharme. Son capítulos de 20 minutos y está en Netflix, así que si os gustan los futuros distópicos os recomiendo echarle un ojo.
Nivel 15: The internsheep
En este nivel recibimos como entrada un archivo comprimido tarball de 11KB, que al ser descomprimido contiene el genoma de unos 100 animales, cada uno en un archivo de hasta 200GB. Lo primero que uno piensa al ver este archivo es que ante un ratio de compresión tan extremo tiene que haber gato encerrado, y no me refiero a su genoma.
Dediqué un precioso viernes a aprender cómo funcionaba DEFLATE, LZ2, los árboles de Huffman y hasta la vida y obra de Mark Adler, sólo para darme cuenta de que estos supuestos genomas son archivos cuyos bytes están todos a cero. No obstante, aprovecharé este conocimiento en futuros posts.
El problema nos pedía que introdujéramos ciertas modificaciones en el genoma de uno de los animales. Estas modificaciones venían definidas como un par (p, b), donde la p indica la posición en el archivo en la que debemos insertar el byte b.
Como no podemos enviar un archivo de 200GB, el problema nos pedía calcular el CRC32 del archivo resultante. El CRC32 es una cadena de control —algo así como la letra del DNI— que se calcula a partir de una secuencia de bytes como un archivo. Es muy frecuente que las descargas online vayan acompañadas de un CRC32 como medida de seguridad.
Así, una vez descargado un archivo podemos calcular su CRC32 byte a byte, y compararlo con el que nos dice la web para saber si ha habido algún error durante la descarga, ya que hasta el menor cambio en un archivo produce una alteración grande en el CRC32.
A primera vista parece un problema fácil: podemos mirar los metadatos del archivo comprimido para saber cuál es la longitud del archivo que quedemos modificar (y por tanto la secuencia de ceros que representa ese genoma), realizar las alteraciones que nos piden y calcular el CRC. Sin embargo, calcular el CRC32 de una cadena tan larga requiere semanas de cómputo en un ordenador convencional.
Por suerte, la librería zlib incluye una función llamada crc32_combine que aprovecha las propiedades de este algoritmo para calcular rápidamente el CRC32 de la concatenación de dos cadenas a partir del CRC32 de sus partes:
crc_combine(crc(A), crc(B), len(B)) = crc(concatenate(A, B))
Así, para calcular el CRC de una lista de 1024 ceros, sólo tendríamos que calcular el CRC de un único cero, usar esta función para calcular el de una secuencia de dos ceros, volverla a usar para calcular una de cuatro… y en definitiva, reducir el orden de este cálculo de forma logarítmica.
De este modo, sabiendo que todos los bytes de los archivos están a cero, podemos ver el tamaño de las secuencias genómicas en los metadatos del archivo comprimido e ir actualizando el CRC32 conforme intercalamos secuencias de ceros con los bytes que debemos insertar.
Nivel 16: The new office
Este problema nos sitúa en una oficina en un gran edificio de hasta 2000 plantas (el Burj Khalifa tiene 163) en el que trabajan muchos empleados. Hay un problema de salubridad importante: el edificio no tiene baños.
Tenemos que calcular el mínimo número de baños a construir, sabiendo que debe haber el mismo número de baños en cada planta, y que todos los empleados deben ser capaces de acceder al baño al mismo tiempo.
Los empleados están organizados en grupos: un empleado pertenece a un único grupo y cada grupo sólo tiene acceso a ciertas plantas. Dado que puede haber hasta 400 grupos de 2000 empleados en el edificio, realizar este cálculo mediante fuerza bruta no es una opción.
Siempre que veo un problema de este tipo, en el que hay muchos elementos distintos (plantas, grupos, empleados) que tienen cierta relación entre sí, algo me dice que usar grafos puede ser la solución. En este caso, el problema se puede resolver mediante grafos de flujo.
Estos grafos se usan habitualmente para modelar redes por las que un flujo recorre una serie de tuberías de una cierta capacidad, como en redes de transporte, circuitos eléctricos o sistemas de fluidos. En este problema, queremos medir el flujo de personas, asegurando que todas las personas que fluyen desde cierto grupo de empleados hacia las plantas autorizadas puedan usar los baños.
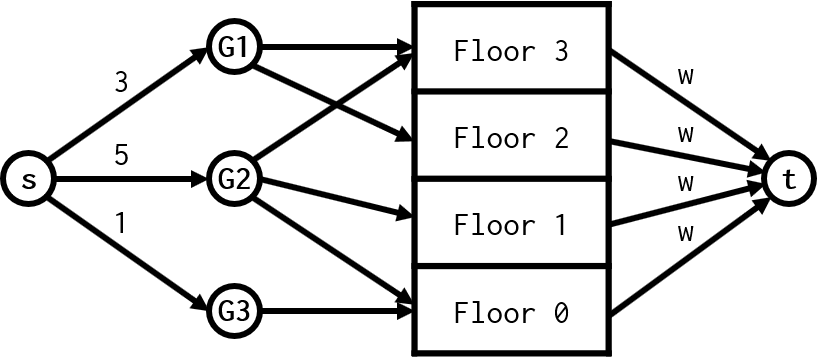
La imagen de arriba representa este problema. Hay tres grupos de empleados: G1, que puede ir a las plantas 2 y 3; G2, que puede ir a las plantas 0, 1 y 3; y G3, que sólo puede ir a la planta 0. Además, G1 está formado por 3 empleados, G2 por 5 y G3 por 1. Esto significa que el flujo de personas que llega a cada grupo es de 3, 5 y 1 respectivamente.
A continuación, estas personas se distribuyen lo mejor que pueden, como si de un fluido se tratase, entre los baños de cada planta; de ahí que las aristas que van de un grupo de empleados a una planta no tengan un límite en su capacidad.
Una vez modelado el problema, resolverlo se reduce a encontrar el menor número de baños posible w, que se corresponde con la capacidad de las aristas de salida en nuestro grafo.
Al diseñar este grafo con el problema original, e ir aumentando w hasta que el flujo que llega a t sea igual al número de empleados, mi ordenador tarda aproximadamente 2 horas en resolver algunos problemas. Pero todavía queda una optimización posible.
Como sabemos que w está en el rango (0, num_empleados), podemos calcular el flujo de salida en el punto medio p = num_empleados / 2. Si p es igual al número de empleados, existe la posibilidad de que podamos encontrar un w menor, por lo que w está en el rango (0, p). En caso contrario sabemos que w está en el rango (p, num_empleados).
Podemos seguir reduciendo el rango hasta encontrar una solución mucho más rápido, concretamente, en un máximo de log2(num_empleados) pasos. Este método se conoce como el método de la bisección.
Nivel 17: Zatoichi
De nuevo, este nivel no tiene más enunciado que una imagen.

Esta imagen es el póster de la película de 2003 Zatōichi, que cuenta la historia de un espadachín ciego interpretado por Takeshi Kitano. Esto nos puede dar una pista de por dónde puede ir la solución.
Además, la imagen esté desordenada y seguramente reordenarla sea el primer paso para resolver este problema. Para hacer esto tendremos que trabajar con los propios píxeles de la imagen y guardarla de nuevo, por lo que toda la meta-información que pueda estar oculta se perderá.
Teniendo esto en cuenta, es probable que no haya metainformación oculta y la clave del problema esté en los propios píxeles de la imagen. Los trucos para esconder información en un archivo se conocen como esteganografía, y una de los más conocidos consiste en esconder información en el bit menos significativo de cada canal de color.
El truco es bastante sencillo. Al representar un color en una imagen, cada pixel se suele representar como un conjunto de 3 bytes, que codifican los valores del rojo, verde y azul entre 0 y 255. Como en la práctica nadie va a notar que un pixel rojo tenga valor 136 o 137, podemos usar ese último bit de cada byte para esconder información.

Si observamos el plano que se crea al usar todos los bits en cierta posición, vemos que los que están en la posición 0 crean una imagen muy estructurada que no tiene nada que ver con la imagen original. Durante el concurso dediqué mucho tiempo a hacer pruebas con este plano: analizarlo, desplazarlo, convertirlo a texto y hasta transformar el XOR de sus tres canales de color en un pentagrama y tocarlo con el piano.
Sin embargo la respuesta era mucho más sencilla: si leemos todos esos bits de arriba a abajo y de izquierda a derecha, extraeremos una cadena que se repite muchas veces.
CONGRATULATIONS, YOU FOUND THE HIDDEN MESSAGE, WILL YOU BE ABLE TO DECODE IT?
E2A089E2A095E2A09DE2A09BE2A097E2A081E2A09EE2A0A5E2A087E2A081E2A09EE2A08AE2A095E2A09DE2A08E20E2A0BDE2A095E2A0A520E2A099E2A091E2A089E2A095E2A099E2A091E2A09920E2A09EE2A093E2A09120E2A08DE2A091E2A08EE2A08EE2A081E2A09BE2A09120E2A09EE2A093E2A09120E2A08FE2A081E2A08EE2A08EE2A0BAE2A095E2A097E2A09920E2A08AE2A08E20E2A09EE2A093E2A09120E2A08BE2A095E2A087E2A087E2A095E2A0BAE2A08AE2A09DE2A09B20E2A0BAE2A095E2A097E2A09920E2A08AE2A09D20E2A0A5E2A08FE2A08FE2A091E2A097E2A089E2A081E2A08EE2A09120E2A09EE2A081E2A085E2A091E2A08EE2A093E2A08AE2A085E2A08AE2A09EE2A081E2A09DE2A095E2A083E2A08AE2A09EE2A095E2A09EE2A081E2A085E2A091E2A08EE2A093E2A08AE2A093E2A0A5E2A08DE2A095E2A097E2A081E2A08DE2A081E2A097E2A08AE2A087E2A087E2A095E2A0BCE2A083E2A0BCE2A09AE2A0BCE2A083E2A0BCE2A09AE2A09EE2A0A5E2A091E2A09DE2A09EE2A08AE2A089E2A093E2A081E2A087E2A087E2A091E2A09DE2A09BE2A091E2A0BCE2A081E2A0BCE2A09A
Un último obstáculo antes de llegar al final. La cadena cifrada está formada por muchos códigos de seis letras que empiezan por E2A0. Una búsqueda en la web del primero de ellos nos revelará que son códigos unicode de caracteres braille.
Por ahí iba la pista de Zatōichi. Si descriframos cada uno de estos caracteres y los traducimos usando el braille inglés (sí, cada idioma usa un braille ligeramente distinto) encontraremos la solución.
Nivel 18: Matters with Formatters
Hemos construido un nuevo servicio, y debido a la falta de coordinación entre dos equipos, cada uno necesita recibir ciertos datos en un formato distinto: Elements Separated by Commas (ESC) y List-Oriented Language with Multiple Advanced Options (LOLMAO).
Dada una cadena válida en uno de los dos formatos, debemos calcular el número mínimo de cambios necesarios para hacerla válida en el otro. No nos importa lo que represente esta cadena, lo único que queremos es que la cadena resultante sea válida en ambos formatos.
Para que una cadena sea válida en formato ESC nos basta con que cada línea del texto contenga al menos dos elementos separados por una coma.
alfa,beta,gamma
,,
foo,bar
test,a[5],asdf
El formato LOLMAO es algo más restrictivo:
- Cada elemento puede ser un literal o una lista.
- Un literal puede contener cualquier símbolo excepto "[", "]" o ",". También puede no tener ningún símbolo, en cuyo caso el literal es una cadena vacía.
- Una lísta empieza con "[" y acaba en "]", y contiene cero o más elementos separados por comas. Estos elementos pueden a su vez ser literales o listas.
- La cadena completa debe ser un literal o una lista.
[[],foo,[[[,],[1,2],5,,],some0literal
with3multiple
lines]]
La cadena de entrada del problema puede ser un texto de hasta 400 caracteres en formato LOLMAO que debemos convertir a ESC, o un texto de hasta 4000 caracteres en formato ESC que debemos convertir a LOLMAO.
En caso de que no sea posible generar una cadena válida en ambos, debemos devolver IMPOSSIBLE. Viendo estas reglas es fácil deducir que toda cadena en ESC debe contener al menos una lista de dos elementos, y por tanto una coma. Para que una cadena con una coma sea válida en LOLMAO, deberá estar rodeada de corchetes. Así, la cadena más pequeña que es válida en ambos formatos es [,] y cualquier cadena menor será imposible.
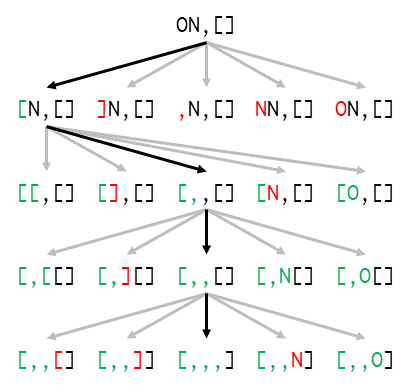
El resto de casos debemos resolverlos explorando cambios en la cadena de entrada. Nos enfrentamos a un problema de programación dinámica, en el que partiendo de un estado inicial —la cadena de entrada— debemos alcanzar un estado final —la cadena válida— en el mínimo número de pasos.
A fin de simplificar las cadenas de entrada, voy a reemplazar cualquier símbolo de la siguiente forma:
def standarize(text):
res = ''
for char in text:
if char in '[],':
res += char
elif char == '\n':
res += 'N'
else:
res += 'O'
return res
A continuación, podríamos representar los estados como cadenas modificadas pero esto permitiría que pudiéramos explorar estados inválidos. Una de las máximas para optimizar la exploración es escoger una representación de estados que permita representar el mínimo número de estados inválidos.
Si nos peleamos un rato con este problema, veremos que cualquier estado se puede reducir a cuatro valores:
- La posición en la cadena: inicialmente será cero, y cada modificación consistirá en alterar el valor del símbolo en esta posición y generar un nuevo estado cuya posición se incremente en uno. Un estado final será aquel cuya posición sea igual a la longitud de la cadena.
- La profundidad: como el formato LOLMAO permite anidar listas, cada vez que encontremos un símbolo
[en la cadena la profundidad aumentará en uno, y cada vez que encontremos un símbolo]la profundidad se reducirá en uno. Inicialmente, la profundidad es cero. - El último símbolo encontrado: inicialmente no estará definido, y vez que pasemos al siguiente estado, tendrá el valor del último símbolo que hemos usado. Nos será útil para evitar combinaciones inválidas como
]O,N[o][. - Si ha habido una coma en esta línea: este valor comenzará siendo falso, siempre que lleguemos a una coma será verdadero, y cuando alcancemos una nueva línea volverá a ser falso. Nos servirá para cumplir la restricción de ESC de tener una coma por línea.
Como esta representación está muy reducida, algunas cadenas distintas se pueden representar mediante un mismo estado. Esto quiere decir que si guardamos en memoria los resultados de nuestra exploración, se reutilizarán con bastante frecuencia.
@lru_cache(None)
def changes(pos, depth, last_char, comma_since_newline):
# TODO compute here the alternatives "alts" as a list of symbols
res = min(
(alt != _text[pos]) + changes(
pos + 1,
depth + (alt == '[') - (alt == ']'),
alt,
alt != 'N' and comma_since_newline or alt == ','
)
for alt in alts
)
return res
Mientras resolvía este problema descubrí ese decorador @lru_cache(size), que se puede usar en cualquier función para almacenar en memoria su resultado, de forma que la próxima vez que se llame a esa función con los mismos argumentos, su resultado no sea calculado de nuevo.
Ya sólo nos queda saber cuándo debemos generar como alternativa cada uno de los cinco símbolos posibles:
- El corchete de apertura
[: si estamos en la posición 0, esta será siempre nuestra única alternativa. En otro caso, podremos usarlo si el símbolo anterior no esO,No]y podemos llegar a cerrar todas las listas abiertas con los caracteres que nos quedan por delante. - El corchete de cierre
]: si estamos en el último símbolo, esta será nuestra única alternativa. En otro caso, podremos cerrar una lista siempre que la profundidad sea mayor a 1. Es decir, siempre que no vayamos a cerrar la lista inicial antes de llegar al final. - La coma
,: en cualquier caso podemos reemplazar el símbolo actual por una coma. - El salto de línea
N: no hay ningún problema que se pueda resolver insertando un salto de línea, por lo que sólo será una alternativa si ese símbolo ya era un salto de línea en la cadena original, ha habido una coma desde el últimoN, y el símbolo anterior no fue]. - Otro símbolo
O: de nuevo, no nos resuelve ningún problema, por lo que sólo será una alternativa si el símbolo en dicha posición en la cadena original ya era de tipoOy además el símbolo anterior no fue].
Con esta aproximación conseguimos resolver el caso de test con facilidad. Pero al llegar al caso de submit la cosa se complica. Algunas cadenas son excesivamente largas y no logramos resolverlas mediante este método. Pero aun nos queda un as bajo la manga.
Como sabemos que las cadenas que deben ser convertidas a LOLMAO tienen como máximo 400 caracteres, cualquier cadena más larga que nos llegue deberá ser convertida a formato ESC. Si encontramos una forma rápida de hacer esta conversión sin romper el formato LOLMAO no tendremos que lanzar el algoritmo de exploración.
En este caso, el truco es el siguiente: en primer lugar, cambiar si fuera necesario el primer símbolo por [ y el último por ]. A continuación, cada vez que lleguemos a un salto de línea que no ha tenido una coma en esa línea, reemplazaremos ese salto por una coma.
De esta forma lograremos reducir el problema rápidamente y todos los casos se resolverán sin problema. El único cambio que tuve que hacer fue aumentar la profundidad máxima de la pila de llamadas debido a mi implementación recursiva de la solución.
setrecursionlimit(10000) # we need to go deeper
Y este fue el último nivel que resolví con éxito durante el concurso. Sin embargo, he dedicado algún tiempo para conseguir resolver el submit del siguiente nivel (sólo conseguí resolver el test) y lo contaré en el próximo post.








Join the discussion