Semantic programming
I believe we are at the threshold of a new programming paradigm. As the latest advancements in AI make it more accessible and closer to a self-hosted utility, we are entering a world in which developers can articulate what they want to achieve in simple natural language terms. I call this paradigm semantic programming.
No one can deny that LLMs have disrupted the way developers code. By July '23, Github reported that 92% of all polled devs were using AI in their work. By November, Snyk reported it was already 96%. The exact figure may vary, but I think it's safe to say most developers are already using AI in their day to day.
I have seen two prominent ways of integrating AI into the workflow. The first is using chatbots like ChatGPT or Bard as a Q&A oracle to which you send your questions or ask for code. The second is as a linter on steroids that you install in your IDE and constantly gives you suggestions coming from a model trained for code completion.
In both scenarios, the workflow involves sending a request to a server—often a supercomputer—that hosts a humungous model trained on vast amounts of data. While there are smaller, self-hostable models, they perform poorly on most AI leaderboards, despite being quite resource-intensive. This is a grim reality, as only big players are able to offer useful AI these days, since the cost of running inference is too high for domestic computers.
It's hard to determine when it will be reasonable to run a good enough pre-trained model locally, because of the constant pace of breakthroughs we're seeing, such as quantization, mixture of experts, LoRAs or distillation. But even if we just consider Moore's Law, it seems it will be a reality soon enough. And when that happens, maybe semantic programming becomes the new normal:
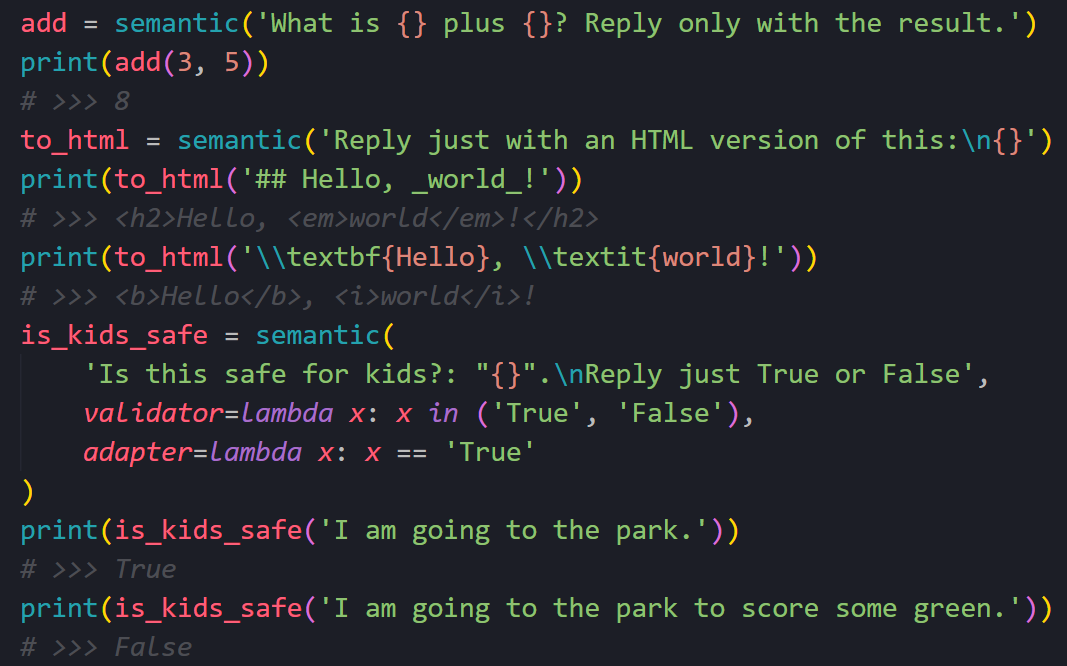
I know, using a trillion-parameter neural network to add three plus five seems cumbersome, even triggering. But so does shipping Chromium with every desktop app just to ignore platform compatibility, yet today it's standard practice with frameworks like Electron. Computer science is a tale of programmers embracing lazy abstractions whenever hardware gets faster.
The add example is an overkill for illustration, and I hope we don't do basic arithmetic this way anytime soon. But methods like to_html would require much more time to handcraft, if that's even possible. Maybe semantic programming becomes simply another tool in the set, same as other niche paradigms like constraint or symbolic programming.
Quality-wise, the main problem is how unreliable the output is. We could have next-token limitations tailored to the problem. For instance, we limit tokens for is_kids_safe output to be either 1 or 0, or dynamically constrain the next token for to_html to adjust to some regex for valid HTML. But these ideas won't get us any further in having a formal understanding of the reasoning behind each answer, nor will it give us mathematical certainity that the algorithm is correct.
Performance-wise, it's easy to see its limitations. Running this tiny example available here requires sending 109 tokens and getting 33 back, which costs $0.000104 with GPT-3.5. This is not a huge price for complex operations with short outputs like is_kids_safe, but longer texts or frequent calls could make the costs add up. Plus, server round trips take ~100ms, which is less than ideal for some seamless code integrations.
Despite all these problems, I'm really excited about this new way of coding. It enables functionalities that were plainly impossible before, like this anything-to-HTML converter. It democratizes coding, allowing people with no previous experience to craft on their own solutions. It shines in contexts where we can be tolerant to errors but can also work in critical contexts, such as law or medicine, by transforming human labor into supervision tasks. And most importantly, it enables, for the first time in history, a way to embed human intuition into code.








Cheers!
Replying to Andrea:
I disagree with Andrea, due to the fact that the mentioned paper does not reflect the reality. It is based only on images. In general, pruning kills the accuracy and the performance of NN. It just happens that for some applications related with classification (e.g. image processing) only, that pruning corrects the weights making the NN to perform better. But in control and signal processing applications, pruning is a killer. This is known since 90s and it is in the literature of NN.Replying to Andrea:
Very nice article. Though I have a different opinion about the democratization of code. Although it might help people to write easier code for performing the desired tasks, in parallel makes them ignorant about the underline knowledge. Although this might be beneficial business wise, it hides the real knowledge form the majority of the people. It is different to try (and struggle) writing code performing FFT on a signal, than using high level abstraction such as do_fft and perform the task.Replying to Andrea:
Thanks for the comment. That's what I mentioned about model distillation: there are very successful models like MiniLM that halves the size of a pre-trained model while keeping ~99% accuracy. Halving a huge model still results in a huge model, but it's definitely something that might end up speeding up progress.Replying to NICKOLAOS PANAGIOTOPOULOS:
Thanks! It's true that you can do FFTs without knowing its insides. And even if you know, there's no need to understand the underlying CPU operations or the physics of transistors, and that's the beauty of abstraction. To me, the key difference is that with semantic programming the opportunity of going deeper is not there, and that is concerning. Or even worse, what if we can solve problems that aren't comprehensible for the human mind? We'd be entirely depending on it.