The longest word chain sequence
You're likely familiar with this game. I recently wondered about the longest possible chain of words that could be formed. This post aims to find it.
There are many variations of this game, so let's set some specific rules:
- The first player says a word.
- The following players must say a word beginning with the last syllable of the previous word, accents ignored.
- A word cannot be repeated.
- Only words from the 23rd edition of the RAE dictionary are valid. Proper nouns, acronyms, and monosyllables are excluded.
- Accents are ignored when chaining words.
Data
First, we need all the words from the Spanish dictionary. Although the RAE doesn't provide a complete list, Giusseppe Domínguez offers one.
Next, we need syllabic decomposition of all the words. This is complex due to many rules and exceptions, but thankfully, Pyphen handles it well.
We end up with a list of 86,993 syllabically separated valid words.
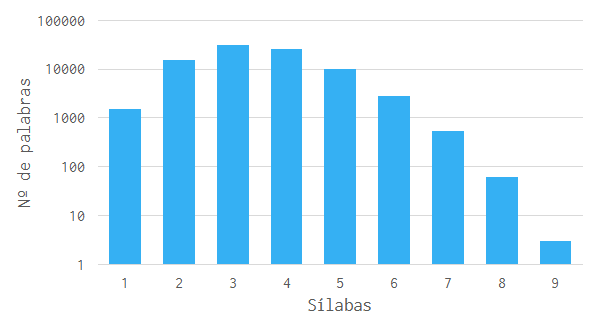
Longest Sequence
To calculate the longest possible sequence, we construct a directed graph with words as nodes and edges connecting chainable words.
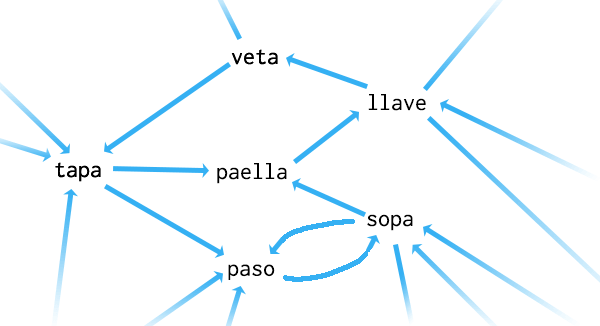
The challenge then becomes finding the longest directed path in this graph. Unlike finding the shortest path, finding the longest in a graph is NP-complete. With a graph of 86,993 nodes and 43,053,416 edges, it would take 1.82 × 101012 years to find the perfect solution, so we must try approximate solutions.
Random Path
Choosing paths randomly, the longest found is only 92 words:
sopa -> pantalla -> llaneza -> […] -> ramuja -> jagüel -> güeldrés
This is due to easily reaching a sink—a word that can be reached but not exited, like güeldrés.
Other Approaches
Other methods to tackle this problem include:
- Performing a depth-first search of the graph and keeping the longest path.
- Always choosing words with more common endings.
- Eliminating sink nodes before random searches.
Can you think of other ways to solve this? What's the longest chain you've managed to create? Feel free to comment with your results.








Si te interesa, no dudes en contactarme.
Un cordial saludo,
Giusseppe Domínguez
Replying to Giusseppe Domínguez:
Muchas gracias Giusseppe. En una investigación que iniciamos hace poco, necesitábamos un corpus de este tipo que tuviera la mayor cantidad posible de palabras, y decidimos usar un repositorio de subtítulos de 234,000 series y películas para extraerlas: http://opus.nlpl.eu/download.php?f=OpenSubtitles/v2018/xml/es.zipPero sin duda una corrección con las definiciones nos será útil si me la puedes facilitar :) espero tu respuesta