If you've ever programmed using a repository, you've likely used a diff tool to compare old and new code, identifying which fragments have changed and which are common to both.

This algorithm might seem simple until we ponder its functionality. For instance, comparing the words schwarzenegger and chuarcheneger, we get the following result:
BEFORE: s c h w a r z . e n e g g e r
AFTER: . c h u a r c h e n e g . e r
CHANGES: - = = / = = / + = = = = - = =
In the change, we have removed 2 letters, modified 2 letters, and added one letter. This analysis, not so simple to perform with our natural intelligence, doesn't have a trivial algorithmic solution either.
Longest Common Subsequence (LCS)
In algorithmics, this problem is known as LCS. The goal of LCS is to find the longest subsequence common to two sequences.
As diff tools only compare two strings at a time, there is a solution using a divide and conquer algorithm, which reduces the problem into smaller ones. Thus, the problem can be defined as follows:
def LCS(X, Y):
if len(X) == 0 or len(Y) == 0:
return []
if X[-1] == Y[-1]:
return LCS(X[:-1], Y[:-1]) + [X[-1]]
else:
return longest(LCS(X, Y[:-1]), LCS(X[:-1], Y))
Where longest is a function that simply returns the longer string:
def longest(X, Y):
return X if len(X) > len(Y) else Y
Having the LCS algorithm (which you can try in Python), it's easy to determine what has been added, deleted, or modified when comparing two strings. However, it's a very slow algorithm. Just by comparing slightly longer strings (like arn. schwarzenegger and ar. chuarcheneger), the execution time skyrockets.
Therefore, using a memory to store results is necessary to avoid computing them more than once. Try it for yourself:
This is the basis of this algorithm, although certain nuances need detailing for it to function correctly; converting the recursive algorithm into an iterative one to avoid exceeding the recursion limit, using data structures that allow more efficient computation, or tokenizing the sequences to consider that each element can be a line of code or a word instead.
No comments
Python Challenge is a website featuring a series of small challenges that can only be solved by coding, preferably in Python. These challenges are organized into levels that get unlicked as you solve the previous one.
The levels have an air of mystery about what needs to be done, encouraging lateral thinking and making it very addictive. Although they can be solved using other languages, the hints and solutions are geared towards Python, to motivate learning more about its libraries and specific functionalities.
In this post, I describe the solutions to the first 20 levels of this challenge that I've managed to solve, with a link to each level in the title. You can find the solution code on Github.
This introductory level simply requires you to calculate the power shown in the image and replace the 0 in the URL with this value. This method of navigation by replacing parts of the URL is common in Riddle games.
Another straightforward level, where the page title itself hints at what to do. We're given a text encrypted by rotation and told which rotation to use, solved using maketrans. Upon doing so, we get this text:
i hope you didnt translate it by hand. thats what computers are for. doing it in by hand is inefficient and that's why this text is so long. using string.maketrans() is recommended. now apply on the url.
Applying the same maketrans to the URL takes us to the next level.
Level 2: OCR
The level itself suggests looking at the source code. Upon doing so, we find two comments, the first of which is:
find rare characters in the mess below:
Followed by a nonsensical string of characters. By only keeping the letters from the string, we obtain the key to the next level.
Level 3: Re
The clue suggests searching for a lowercase letter surrounded by exactly three uppercase letters on each side. Using regular expressions, we search [^A-Z][A-Z]{3}([a-z])[A-Z]{3}[^A-Z] and find several letters that together form the solution to this level.
Clicking on the image, we're taken to a page ending in ?nothing=12345 with the text:
and the next nothing is 44827
Changing the number in the URL takes us to another similar page, again pointing to a different number. It seems we could be doing this all day, so it's time to use an HTTP request library, such as urllib (included in Python) or requests.
Through navigation, we encounter an exception: a level where one of the codes must be divided by two. Other than this, the level isn't too complicated; we follow 250 pages and reach the link to the next level.
The clue this time is in the level title, which suspiciously sounds like Pickle, Python's object serialization library.
In the source code, we find a pickle file. Upon importing and examining it, we see it's a list of lines of text. Each line, instead of being a list of characters, is a list of pairs (character, repetitions). Reconstructing the text, we get a nice ASCII art:
This level is quite similar to the 4th. We're shown an image of a zipper (zip in English), and changing the image extension from png to zip, we find a compressed file with many txt files and a readme, which says:
welcome to my zipped list.
hint1: start from 90052
hint2: answer is inside the zip
Navigating the files the same way as in level 4, this time using the zipfile library, we eventually find the text "collect the comments". However, this text is not the solution to the problem.
Since zip files have a comment field for files, we keep the comments from each file as we navigate. When combined, they again form a message in ASCII art.
In this case, the ASCII art is meant to mislead. The word it forms is not relevant, but the characters that make up the letters are.
This level shows us an image with a strange pattern of gray tones. Reading the gray intensity of each of the squares, we get the following series:
105 110 116 101 103 114 105 116 121
Converting each of these numbers into an ASCII character, we get the word integrity, the key to the next level.
In the source code of this level, we find a username and password that are compressed using bzip2. Using Python's bz2 library, we get the username (huge) and password (file). Clicking on the image, we're asked for a username and password, which are the ones we just found, taking us to the next level.
Again, by looking at the source code, we find two strings, this time two sequences of numbers. After some analysis, we realize that the even numbers are close to each other and so are the odd numbers in both sequences. Treating each sequence as a list of number pairs, we can use the ImageDraw module of the PIL library to construct a figure that gives us the key to the next level.

By the way, if we put 'cow' as the solution, it tells us we got the gender wrong, a very accurate guide not to mislead the player who solved it.
In this level, we find an image with a link to a sequence of numbers. Since it's a sequence of integers, we can search on OEIS to see if it's known, and indeed it is. It's the Look and Say sequence, which consists of describing the previous number in numbers.
The series works like this:
- The initial element is one.
- The next element is the description of what we see in the previous one. As we see "one one", the element is 11.
- We repeat the previous action, in this case, we see "two ones", so the element is 21.
- Next, we see a two and a one; 1211.
- We could continue manually until we reach the 30th term of the series required by the problem, but since it has 5808 digits, it's better to program a generator.
We observe an image with a strange effect, like those WhatsApp images that have one thumbnail and open to another thing entirely. Looking closer, we see that two images are interleaved, and by keeping the pixels with odd coordinates, we get the key for the next level.

Again an image with a strange effect on its pixels. I confess that I spent quite a while on this level. After gaining some experience with these types of challenges, I suspected something when I saw that the image of the level was called evil1.jpg, so I tried evil2.jpg and bingo! The image explains that we should change the extension to gfx.
Interestingly, trying evil3.jpg we encounter the text "no more evils…", and trying evil4.jpg we find an image that is actually a text file that says: "Bert is evil! go back!".
After much frustration, I decided to open the image with a hexadecimal editor, and I found the key to solving the level, the tag ÿOÿà that identifies the beginning of a jpeg file.

The tag appears discontinuously several times, as does the GIF8 tag. If we take one out of every 5 pixels and convert it into 5 images, we get the key for the next level: disproportional.
Looking at the source code, we find a link to an XML-RPC server. By doing listMethods() on it, we find a single defined method, phone. Since the level's clue is "phone that evil", and we know Bert is evil from the previous level, we call Bert and get the solution to the level.
At this point, the levels become quite challenging and less intuitive. I lost many hours because calling bert yielded no result if the B wasn't capitalized.
This level is relatively simple compared to the previous one: we find an image of a spiral (like a cinnamon roll) and below, an image that, when opened, is only 1px high.
By rolling it into a spiral shape, we get an image of a cat. Entering cat in the URL shows us the cat, named Uzi. Putting Uzi in the URL takes us to the next level.
We find a peculiar image of a calendar from the year 1XX6, where February had 29 days, and Monday was the 26th. The clue in this case is in the source code, and it's "buy flowers for tomorrow". Since the question is whom?, a simple Wikipedia search for January 27th gives us a long list of people born on that day. Limiting the search to years following the 1XX6 pattern and that fell on a Monday, we get a single result: the birth of Wolfgang Amadeus Mozart.
After several levels of this style, it becomes quite intuitive to solve. If we join the entire image into a single 1px high strip, and introduce a break for each repetitive sequence of white and pink pixels we find, we get the key to the level:

Level 17: Eat?
We encounter an image of cookies (a classic hint about cookies) with a small image referencing level 4.
Returning to this level, we notice that a cookie tells us "you should have followed busynothing". Since the URLs of this level were of the type ?nothing=..., we change the first one to ?busynothing=... and start following the chain, while saving the information given by the info cookie. We get the following phrase:
is it the 26th already? call his father and inform him that "the flowers are on their way". he'll understand.
A quick search reveals that his father was Leopold Mozart. Since we're told to call him, we use the phone from level 13 to call Leopold, who tells us 555-VIOLIN. Replacing the URL with VIOLIN takes us to the Leopold page, asking us what we want.
Unfortunately, I haven't managed to advance beyond this point yet. If I continue making progress, I'll update this post.
2 comments
A while back, I had the idea to design reversible noise, where the function f used for both encrypting and decrypting is the same, so that f(text, password) = f(encrypted, password).
 XorCrypt
XorCrypt
Read on if you're interested in how it works.
ROT-13 Encryption
Reciprocal ciphers have been around for ages. A classic example is the ROT-13 Cipher, which rotates a letter 13 positions in the alphabet. With an alphabet of 26 letters (excluding ñ), repeating this operation brings you back to the original letter: A -> N and N -> A.

XOR Encryption
My aim was to create a somewhat more secure cipher that requires a password for encryption/decryption. This is where XOR Encryption comes into play, based on the XOR (⊕) logical operation, eXclusive OR:
This operation can be applied to a number at the bit level. For example, 220 ⊕ 153 = 69.
The beauty of XOR is its reciprocity: just as 220 ⊕ 153 = 69, 220 ⊕ 69 = 153. Given any number A, the operation A ⊕ P = B and B ⊕ P = A. Thus, we can define a password P, enabling us to reversibly encrypt any string by assigning a number to each letter.
For example, if our string is "HELLO WORLD", our password is "PASSWORD", and we assign each letter a position in the alphabet (0 for space), we get the encrypted string "IFMMP XPSME".
Reapplying the operation with "PASSWORD" and "IFMMP XPSME", we get back our original string. However, two issues remain:
- What if the input string and the password have different lengths?
- If someone has an unencrypted string and its encrypted version, how do we ensure they can't figure out our password?
Handling Different Length Strings
A simple solution is to pad the password with spaces until it matches the text length. However, this changes nothing, as A ⊕ 0 = A. For instance, with "HELLO WORLD THIS IS A TEST", we get "IFMMP XPSME THIS IS A TEST".
Another option is to pad the password with a non-space symbol. Or, for less predictability, loop the password. In this way, for "HELLO WORLD THIS IS A TEST", using "PASSWORDPASSWO" as the password, the encrypted result is "IFMMP XPSMETHIS IS A TEST".
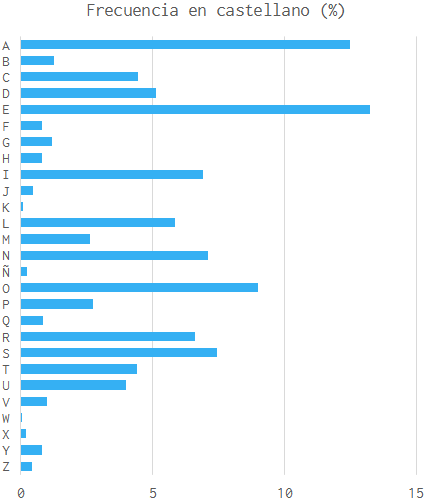
However, this solution is also insecure, as encrypting long texts would make it easy to spot frequently repeating letter combinations, allowing password guessing through frequency analysis. But there's still a trick up our sleeve.
Hash Functions
In cryptography, hash functions are techniques that encrypt a string at low cost but with a prohibitively high decryption cost, sometimes taking millennia.
This is the case with the SHA-256 function. Using this function, we can encrypt the password and safely apply XOR encryption. To create a longer password, we would use a list of salts. I won't go into detail on this to keep the post brief, but feel free to ask more in the comments.
Conclusions
After all this, we have achieved a moderately secure reciprocal cipher and, more importantly, learned a bit about cryptography.
If you're interested, you can try this cipher yourself on this page. It's a version to which I've added more characters.
1 comment
You're likely familiar with this game. I recently wondered about the longest possible chain of words that could be formed. This post aims to find it.
There are many variations of this game, so let's set some specific rules:
- The first player says a word.
- The following players must say a word beginning with the last syllable of the previous word, accents ignored.
- A word cannot be repeated.
- Only words from the 23rd edition of the RAE dictionary are valid. Proper nouns, acronyms, and monosyllables are excluded.
- Accents are ignored when chaining words.
Data
First, we need all the words from the Spanish dictionary. Although the RAE doesn't provide a complete list, Giusseppe Domínguez offers one.
Next, we need syllabic decomposition of all the words. This is complex due to many rules and exceptions, but thankfully, Pyphen handles it well.
We end up with a list of 86,993 syllabically separated valid words.
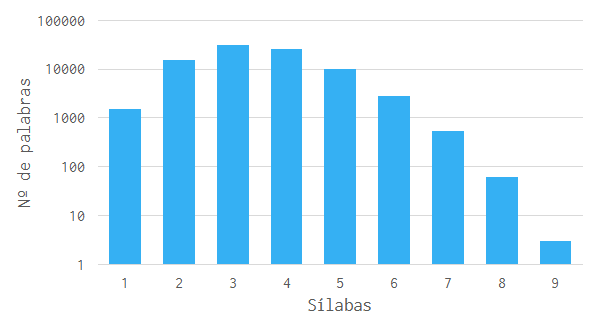
Longest Sequence
To calculate the longest possible sequence, we construct a directed graph with words as nodes and edges connecting chainable words.
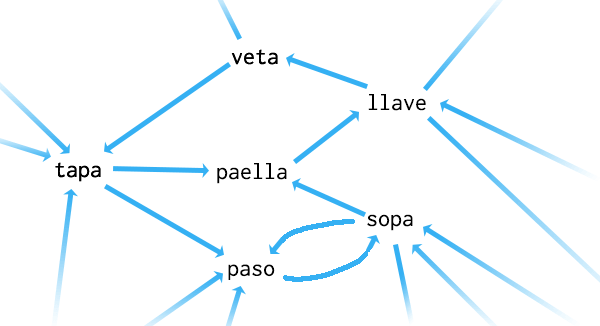
The challenge then becomes finding the longest directed path in this graph. Unlike finding the shortest path, finding the longest in a graph is NP-complete. With a graph of 86,993 nodes and 43,053,416 edges, it would take 1.82 × 101012 years to find the perfect solution, so we must try approximate solutions.
Random Path
Choosing paths randomly, the longest found is only 92 words:
sopa -> pantalla -> llaneza -> […] -> ramuja -> jagüel -> güeldrés
This is due to easily reaching a sink—a word that can be reached but not exited, like güeldrés.
Other Approaches
Other methods to tackle this problem include:
- Performing a depth-first search of the graph and keeping the longest path.
- Always choosing words with more common endings.
- Eliminating sink nodes before random searches.
Can you think of other ways to solve this? What's the longest chain you've managed to create? Feel free to comment with your results.
3 comments