Developers spend at least one third of their time working on the so-called technical debt [1,2,3]. It would make sense then that non-technical people working with developers had a good understanding of an activity that takes so much of their time. However, this abstract concept remains elusive for many.
I believe this problem has to do with the name "technical debt" itself. Many people are unfamiliar with debt, and thinking of how debt applies to software is not straighforward. But there is a concept that is way more familiar and might be more familiar: clutter. In software, as in any other aspect of life, clutter follows three basic rules:
- It increases with normal operation.
- Accumulating it leads to inneficiencies.
- Managing it in batches is time efficient.
Think of how it applies to house clutter: (1) everyday life tends to get your house messier if nothing is done to prevent it, (2) a messy home makes your day to day slower, and (3) the total time required to clean twenty dishes once is less than cleaning one dish twenty times. I empirically measured myself in this endeavor; it took me 5:10 to clean twenty dishes, versus the 15:31 that I spent cleaning them one by one over the course of multiple days.

The things I do for science
Due to the third rule, keeping the clutter at zero is a suboptimal strategy. I guess this is why in any given workplace we find clutter to some extent; think of office desks, factory workshops, computer files, email inboxes… and codebases. Just as it's inefficient to clean a single dish immediately after every use, in software development, addressing every instance of technical debt or "code clutter" as soon as it arises is not always practical or beneficial.
However, due to the second rule, letting the clutter grow indefinitely is also not a good strategy, because the inneficiencies created by the clutter can be bigger than the time required to keep it at bay. One of the hardest tasks in management is striking a good balance between both, because it's all about solving this optimization problem.
To find the optimum amount of clutter, you'd need to know how much does clutter grow depending on which operation you do, and how much easier it is to reduce clutter when you have more of it. But none of those two parameters is easily readable when looking at a project, so the way to steer a project is usually based in prior trial-and-error. Plus, those parameters are not static over time, which just makes it even worse.
I have seen many practices targeted at keeping technical clutter at bay, such as dedicating a day each week or allocating a percentage of the sprint backlog for refactoring. But I haven't found any foolproof data-based method for managing it, maybe because the distiction between adding new functionalities and de-cluttering is not always clear-cut and that makes it hard to report on.
What is clear is that, managing clutter requires a shift in the way we see it: it's not an accidental problem introduced by inneficient development, but rather an unavoidable byproduct of development.
No comments
It's no secret that authenticating into services is an unresolved topic. With time, we have managed to make them more secure, but that was at the expense of user experience. The new generation of mail codes and authenticator apps has moved us from the ease of one-click browser autocomplete to complex ordeals involving multiple steps and sometimes multiple devices.
Last month, I was logging into Notion after it automatically logged me out, and I couldn't help but think "It feels like I'm logging in here every second week; maybe I'm doing something wrong." After a long examination of the settings, I decided to open a ticket asking if the session length was indeed that short. The response from Notion's team was prompt and specific, a great example of customer service. However, the content of the answer was less pleasing.
Notion is not alone in this; many other services enforce similarly short sessions and uncomfortable methods. This has me pondering the evolution of our authentication methods, from their ancient beginnings to modern complexities. Let's take a look at the history of authentication methods and rate them on two scales: user experience and security.
The first recorded password in western history is the book of Judges. Within the text, Gileadite soldiers used the word "shibboleth" to detect their enemies, the Ephraimites. The Ephraimites spoke in a different dialect so that they would say "sibboleth" instead. Experience ★★★★★: you just had to say a word. Security ☆☆☆☆☆: there's a single word to authenticate multiple users and it can be cracked by learning how to spell it.
Ancient Romans also relied on passwords in a similar manner called them "watchwords". Every night, roman military guards would pass around a wooden tablet with the watchword inscribed and every military man would pass the tablet around until every encampment marked their initials. During night patrols, soldiers would whisper the watchword to identify allies. Experience ★★★☆☆: you just had to say a word but you have to memorize it every day. Security ★☆☆☆☆: it changes every day, but it's still a single word, and without a "forgot password" button, a wrong answer would mean a spear in the gut.
Fast forward to the '20s, alcohol became illegal in the US, and speakeasies (illegal drinking establishments) were born. To enter the speakeasy, people had to quietly whisper a code word to keep law enforcement from finding out. Code words were ridiculous, to say the least: coffin varnish, monkey rum, panther sweat, and tarantula juice, to name a few. Experience ★★★★☆: you just had to say a word, and they were made to be memorable. Security ★☆☆☆☆: it's a single word, and it's not even a secret, but at least you don't get stabbed for getting it wrong.
The first recorded usage of a password in the digital age is attributed to Dr. Fernando Corbató. In the 60's, monolithic machines could only work on one problem at a time, which meant that the queue of jobs waiting to be processed was huge and a lot of processing time was lost. He developed an operating system called the Compatible Time-Sharing System (CTSS) that broke large processing tasks into smaller components and gave small slices of time to each task. Since multiple users were sharing one computer, files had to be assigned to individual researchers and available only to them, so he gave every user a unique name and password to access their files stored in the database. However, these passwords were stored in a plaintext file in the computer and there were a few cases of accidental and intentional password leaks. Experience ★★★☆☆: you have to remember a user and password. Security ★★☆☆☆: it's one per user, but they're stored in plaintext.
To prevent the problem of plaintext passwords, Robert Morris and Ken Thompson developed a simulation of a World War 2 crypto machine that scrambled the password before storing it into the system. This way, the system could ask for the password, scramble it, and compare it to the scrambled password stored in the system, a process called one-way hashing. This simulation was included in 6th Edition Unix in 1974, and got several improvements up to our days, but the basic idea remains the same. Experience ★★★☆☆: you have to remember a user and password. Security ★★★☆☆: it's no longer plaintext, but stealing it would still give you access to the system.

Over time, many different problems arised from the fact that people use the same password for multiple services, so the industry started to push for unique passwords for each service. This was a problem for users, since they had to remember a lot of passwords, and password managers were borned. The first password manager was developed by Bruce Schneier in 1997, and currently every major browser comes with a built-in one, often with an option to generate strong passwords and store them for you. Experience ★★★★☆: you have to remember a master password, but the browser remembers the rest. Security ★★★★☆: it's no longer plaintext, but the master password is the weakest link in the chain.
Phishing attacks and data breaches have made passwords a liability, so the industry has been pushing for multiple-factor authentication (MFA) for a while now. 2FA is a method of authentication that requires two different factors to verify your identity. The first factor is usually something you know, like a password, and the second factor is something you have, like a phone. This way, even if someone steals your password, they still need your phone to log in. There is a myriad of ways to implement 2FA, but the most common ones are SMS codes, authenticator apps, and mail codes. It is often used in conjunction with very short session lengths. Experience ☆☆☆☆☆: you have to remember something, have a phone or mail app, and it requires multiple steps. Security ★★★★☆: it's no longer a single factor, but it's still vulnerable to phishing attacks.
I, like most people, hate passwords and all means of authentication bureaucracy. And it looks like we're now at the lowest point in history in terms of UX. There is still hope with the rise of Single Sign-On (SSO) and biometrics. And certainly passkeys, which are getting a lot of traction lately, are a step in the right direction. But only time will tell if their adoption will be widespread enough to make a difference or if we'll be stuck in this dark age of authentication experience for a while.
Related posts:
13 comments
Hace unos meses contraté la línea de móvil con Vodafone/One, con un contrato que ofrecía la tarifa Zero Rating. Básicamente, consistía en no contar en el consumo de datos algunas aplicaciones de mensajería: Telegram, Line, Whatsapp, y algunas más.
En su momento me pareció muy buena idea, podría usar los bots de Telegram para no consumir datos al descargar vídeos de YouTube, canciones, o convertir archivos a otro formato. Y no me di cuenta de la cara oculta de esta tarifa.
Supongamos que mañana diseño un nuevo servicio de mensajería, con muchas funcionalidades, tan bueno que merecería estar en el top de aplicaciones descargadas. Un gran número de usuarios no lo descargarán, simplemente porque con otras alternativas no consumen datos.
Y puede ir a más. Eligiendo qué aplicaciones tienen permitido hacer tal cosa y qué otras no, estamos abriendo la veda a estrategias como la de MEO en Portugal.
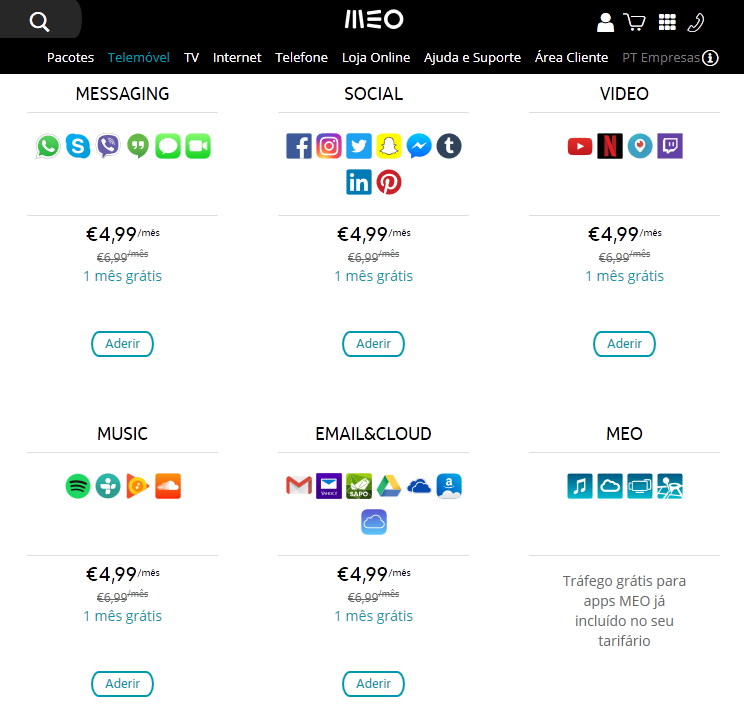
Gran parte de la belleza de Internet reside en su neutralidad. Para que podáis estar leyendo mi web, los bytes van desde mi servidor doméstico hasta vosotros siguiendo el mismo camino que seguirían al usar Google o Facebook. Sin embargo, al matar la neutralidad en la red, se está permitiendo la creación de autopistas de peaje, vías rápidas que obligan a las webs a pagar cierta cantidad a las operadoras para poder funcionar a la máxima velocidad.
Estas prácticas están prohibidas en la Unión Europea, aunque en España la interpretación ha sido bastante laxa. Seguramente os suenen casos de operadoras que bajan la velocidad a usuarios que utilizan descargas P2P o VoIP, o que directamente las bloquean.
Esta semana en EEUU se está decidiendo algo parecido. Muchos usuarios están haciendo todo lo posible por evitar que la nueva ley entre en vigor. Y allí las acciones de algunas operadoras han sido bastante más malignas. Por ejemplo, AT&T censuró un directo de Pearl Jam por las críticas de su cantante al en aquel entonces presidente George Bush.
En definitiva, podemos decir que estamos mejor que la mayoría, aunque podríamos estar mejor. Y siendo prácticos, existe otra neutralidad en la red que merece más nuestra atención, la App Neutrality: Google y Apple comparten un duopolio que les da potestad absoluta para decidir incluir o no incluir ciertas aplicaciones en sus stores, y colocarlas en una posición más alta o más baja en el ranking.
Y también podríamos hablar de la Search neutrality, aunque eso da para otro post.
2 comments